

We build computer systems around abstractions. The right abstractions are timeless and versatile, meaning they apply in many different settings. Such abstractions make developers’ lives easier, and allow system developers and researchers to optimize performance “below the hood”, by changing systems without breaking the abstractions. In this post, I will argue that the abstraction of dataflow computing is a remarkably powerful one. Mapping computations into dataflow graphs has given us better, more fault-tolerant and scalable distributed systems, better compilers, and better databases. Dataflow also has the potential to enable new system designs that solve other — seemingly unrelated — real-world problems, such as making it easier and cheaper to comply with privacy legislation like the European Union’s GDPR, or California’s recent CCPA.
A Brief Introduction to Dataflow Computing
The key idea behind dataflow computing is to express computation as a dataflow graph. Each vertex of a dataflow graph represents an operation, and each edge represents a data dependency. For example, a dataflow graph for the function f(x, y, z) = x * y + z might look like this:
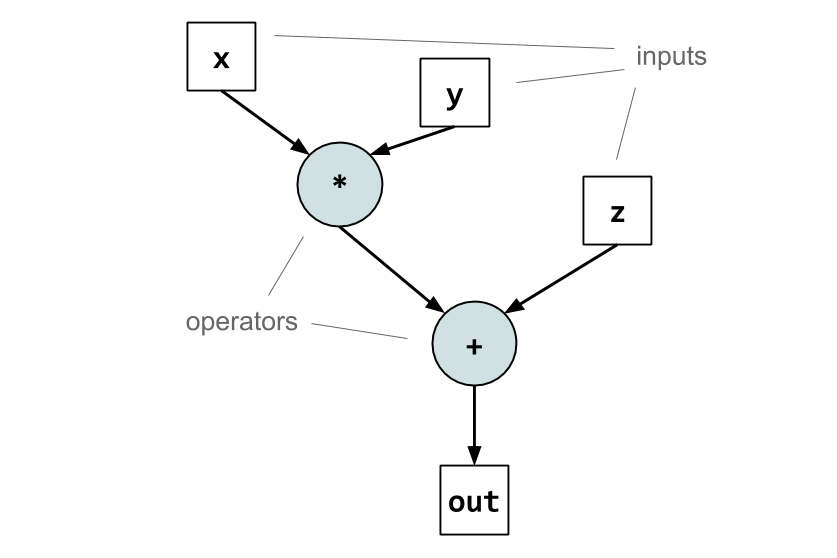
In this graph, boxes represent input and output data. Circles represent operators (the blue “+” and “*”), and arrows represent data dependencies. The graph structure expresses that when the dataflow executes, x gets combined with y via multiplication, and that the result gets combined with z via addition. Think of this as x and y “flowing” along the edges into the “*” operator, and the multiplication result flowing into the subsequent addition operator. Importantly, the graph makes it explicit that the multiplication cannot execute until both x and y are available, and that the addition requires both the result of the multiplication and the value of y to execute!
Over time, different uses of the dataflow abstraction have evolved this basic notion in a variety of ways. But, as we will see, the core idea of explicit data dependencies and structured computation is extraordinarily powerful.
Origins: Computer Architecture in the 1970s and 1980s
Dataflow computing originated in computer architecture proposals in the 1970s and 1980s, with pioneering work by Jack Dennis and Arvind, as well as many others. The central idea was to replace the classic von Neumann architecture with something more powerful. In a von Neumann architecture, the processor follows explicit control flow, executing instructions one after another. In a dataflow processor, by contrast, an instruction is ready to execute as soon as all its inputs (typically referred to as “tokens”) are available, rather than when the control flow gets to it. This design promised efficient parallel execution in hardware when many “tokens” were ready to execute.
Unfortunately, however, dataflow machines turned out to be more difficult to build and make performant than researchers had hoped. At the same time, the rapid performance advances in competing traditional processors made it difficult for dataflow hardware to achieve traction. For a decade and a half, dataflow ideas receded into the background — at least in the systems community. (Much fantastic work happened during this time in other communities, e.g., compilers used dataflow abstractions for program analysis; and database query planners and execution models, such as Volcano, were trailblazers of future use cases for dataflow abstractions.)
Resurgence: Big Data
The early 2000s brought the age of large internet services, and consequently the need to process unprecedented amounts of data, such as web search indexes. This called for computation models that harness parallelism, but which can also recover from failures due to crashing computers or lost network connections. MapReduce, the first scalable, easy-to-use, and fault-tolerant programming model for “big data” — albeit not phrased in terms of dataflow in the original paper — expresses a computation that trivially maps to a dataflow graph:
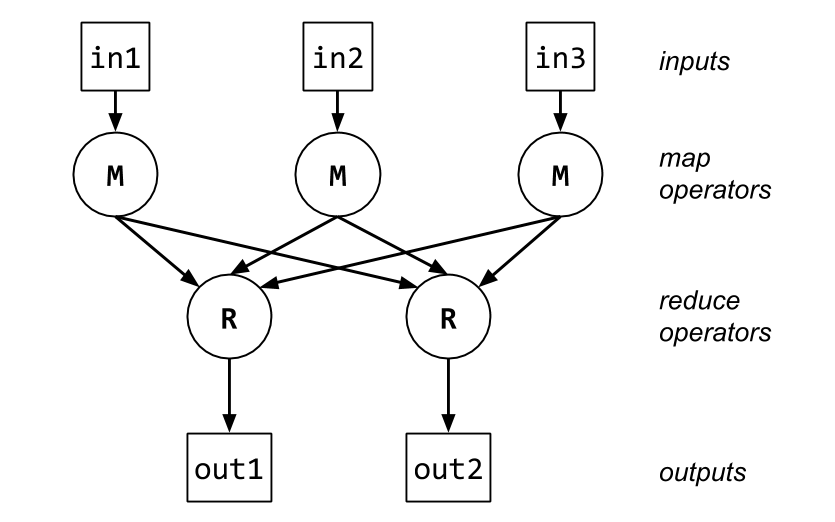
One difference with the original dataflow architectures is that the data size is much larger here: instead of individual integers, the “tokens” flowing through the graph are large amounts of data. But the underlying principle is the same! Each input data item “flows” to a map operator, which applies an operation and sends parts of the data to flow to different reduce operators, which again apply an operation on their inputs, and finally produce output. Observe that this computation is the ideal case for dataflow parallelism: many inputs are available, map and reduce operators can process in parallel, and the edges specify the computation’s dependency structure.
This is where a second key insight comes in: the structure of a dataflow graph specifies exactly what computation executes, so if a failure occurs, the graph describes exactly how to recompute what’s missing! This works even if the failure destroys a part of the output, intermediate data, or data flowing along edges in the graph, assuming the computation is deterministic (a restriction that all practical fault-tolerant big data platforms require).
In other words, a dataflow abstraction offers precisely what we need to process large data sets efficiently: a structured computation with explicit dependencies that the execution layer can automatically parallelize by executing different, independent parts of the dataflow graph at the same time on different computers. Dryad made this insight explicit, and generalized the graph structure beyond the fixed graph imposed by the MapReduce model; and widely-used Apache Spark relies on “lineage” information (the dataflow graph structure!) to reconstruct missing data with minimal recomputation on failure. Other work explored self-modifying dataflow graphs, and ways to translate from high-level programming languages into efficient dataflow graphs.
Broadening Scope: Dataflow Everywhere!
Many other systems that interact with large data have since drawn on the dataflow abstraction for their design.
For example, machine learning frameworks like TensorFlow represent model training and inference as dataflow graphs, and the state transitions of actors (e.g., simulators used in reinforcement learning training) can be represented as dataflow edges, too.
Other research has extended the original dataflow graph abstraction for streaming computations. Instead of evaluating the dataflow graph once, with all inputs set at the beginning and all outputs produced at the end of evaluation, a streaming dataflow system continuously executes the dataflow in response to new inputs. This requires incremental processing and a stateful dataflow. In this setting, new inputs from a stream of input data combine with existing computation state inside the dataflow graph (e.g., an accumulator for a streaming sum). This was perhaps first observed and exploited by declarative networking architectures like P2 and the Click modular router, which compile high-level protocol descriptions into efficient dataflow pipelines. A few years later, streaming big data processing systems like Naiad and Flink combined stateful dataflow and the throughput of data-parallel “big data” systems (like Dryad/MapReduce) into efficient models for executing such streaming analytics pipelines at scale, and Frank McSherry has achieved impressive performance for a variety of incremental graph processing problems (as well as other computations) using a dataflow system.
Most recently, streaming dataflow has been instrumental in building efficient materialized view maintenance systems designed for web applications and dashboards. For example, Noria is a database-like storage system that incrementally updates materialized views via dataflow. Noria’s materialized views make read-heavy web applications efficient, and Noria also simplifies such applications, as it obviates the need for separate caching infrastructure (e.g., memcached) or application code that invalidates cache entries when data changes. Noria goes further than prior stream processing systems in making the dataflow only partially stateful, combining eager dataflow processing with lazy evaluation for rarely-needed results.
Where Next?
The crucial power of the dataflow abstraction lies in its rigid, explicit computation structure and the efficient execution strategies available to implement it. This combination of properties still has unexplored potential, and turns out to be useful in unexpected settings.
One perhaps surprising domain is compliance with privacy legislation like the European Union’s recent General Data Protection Regulation (GDPR). The GDPR requires that companies must identify, on request, what data stored on their systems relates to a specific end-user. The process for complying with such requests is often manual, and particularly difficult and costly for small and medium-size companies. But knowing the exact dependency structure of the computation that produced a piece of information — perhaps a cache entry for your social media feed, aggregated user data, or a marketing email distribution list — may help us simplify and automate this task!
Again, dataflow has a chance to shine here. While systems research has primarily looked at dataflow from the perspective of parallel processing performance and fault-tolerance, it may also help with compliance. For example, future “privacy-compliant by construction” systems may use dataflow to express analyzable, reversible, and high-performance ways to process information, building ideas from the provenance-tracking literature into a practical, performant system. Or a materialized-view system may maintain “featherweight”, personalized materialized views for each end-user of an application, speeding up their queries and enforcing global and personalized policies (e.g., their privacy settings); all based on an understanding of the computation structure.
To build this and other use cases around dataflow, systems research must continue to innovate in how we build systems around the dataflow abstraction. For example, we may need new systems that can handle substantially larger dataflow graphs than today’s systems can, support for non-determinism, and tools that can reason about dataflow graphs and verify properties we want enforced — such as, perhaps, forcing companies to only use our data in ways that we have consented to!
Bio: Malte Schwarzkopf is an Assistant Professor in the Department of Computer Science at Brown University. His research covers computer systems, with a specific focus on novel and high-performance parallel and distributed systems.
Disclaimer: This post was written by Malte Schwarzkopf for the SIGOPS blog. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGOPS, or their parent organization, ACM.