

Editor’s notes: We invite SIGOPS award winners to write about backstories behind the award-winning work. In this article, Anuj Kalia shares his journey of his PhD dissertation–“Efficient Remote Procedure Calls for Datacenters”–which received the Honorable Mention for the 2020 Dennis M. Ritchie Award. Anuj is a Senior Researcher in Azure for Operators’ Office of the CTO. He received his PhD from CMU advised by Professor David Andersen.
I didn’t know it at that time, but my dissertation work started in 2013 with my first-semester distributed systems course project, when my advisers, with great foresight, suggested that I look for ways to improve upon the conventional wisdom surrounding then recent in-memory key-value stores based on Remote Direct Memory Access (RDMA), like Pilaf. This sent me on a quest for fast communication software designs for datacenters, exploring the new world of modern datacenter interconnects with in-network features, but eventually coming back to a traditional end-to-end design.
An overview of key-value stores and Remote Direct Memory Access
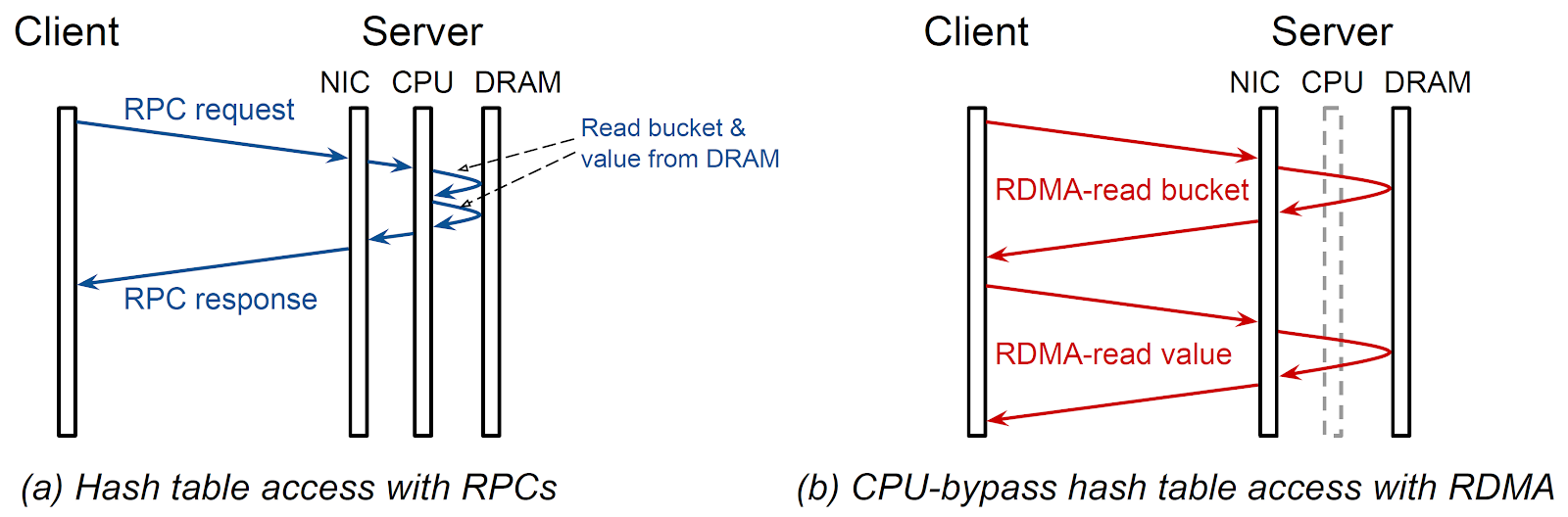
Internet datacenters use in-memory key-value stores like Memcached and Redis for a variety of large-scale applications, like caching the results of queries from a slow disk-based database. In a traditional key-value store, client-side software requests an item from the server by sending it a Remote Procedure Call (RPC) request over the datacenter network. Upon receiving the request, server-side software retrieves the requested data from an in-memory data structure (e.g., a hash table), and sends a response message to the client. The Pilaf work observed that this approach burns many server CPU cycles in the networking stack and data structure access, reducing throughput and increasing latency. In Pilaf, clients can access the key-value store with zero server-side CPU use, via a technology called Remote Direct Memory Access.
RDMA is a feature provided by some networks that allows a client machine to access a server machine’s memory directly, i.e., without involving the server’s CPU. Developed in the supercomputing community starting with the Virtual Interface Architecture in 1998, RDMA-capable interconnects like InfiniBand dominate the Top-500 supercomputers today. At a basic level, RDMA works as follows: clients send RDMA read/write requests to a remote server. The server’s RDMA NIC performs local Direct Memory Access (DMA) read/write operations in response to client requests, and sends a reply.
Pilaf organizes its key-value store as a hash table in the server’s memory, which clients can access with two RDMA read operations: The client’s first RDMA read into the hash table’s index retrieves the value’s address and size in the server’s memory, and the second RDMA read retrieves the value.
The RDMA vs. RPC debate
A fundamental drawback of using RDMA to access remote data structures is that the client must use multiple network round trips if the server-side data structure uses pointer-based indirection. For example, the hash table in Pilaf has one level of indirection, and therefore requires two dependent RDMA reads per access. Nevertheless, the measurements in Pilaf and subsequently FaRM found that using even two RDMA reads was faster than using one RPC. This was unintuitive to me because an RPC requires fewer network round trips and network packets than two RDMA reads.
I started working on optimizations to build faster RPCs, but I found myself thrown into a maze of messy hardware details that affect performance but had little documentation or guiding materials: the network protocol implemented in NIC hardware, PCIe bus transactions, and NIC hardware architecture implementations that aren’t disclosed by vendors. Learning my way around this maze required reading dense specifications and device driver code, inspecting vague hardware counters, and talking to NIC vendor employees over drinks at conferences. (The latter is where a well-cited number about the amount of SRAM in a popular NIC model comes from.)
In my first paper, we show that by being cognizant of NIC and PCIe hardware details, an RPC can be as fast as a single RDMA read. Our work applies a variety of optimizations that make this performance possible. For example, we disable transport-level acknowledgments by using the RPC messages as implicit ACKs. Optimizing at a lower level, we omit even some PCIe bus acknowledgements using a similar principle. With these RPCs, we implement a key-value store called HERD that has nearly twice the throughput and half the latency of prior RDMA-based key-value stores that bypass the server’s CPU.
HERD’s latency advantage from using fewer datacenter network round trips is fundamental because the speed of light bounds round trip latency. On the other hand, CPU-bypassing designs have the fundamental advantage of lower CPU use at the server. This tension gave rise to a lively and long-running debate around RDMA vs RPCs for various applications.An important lesson from HERD was that hardware-centric optimizations are crucial to the performance of networked applications, sometimes deciding which system design (e.g., one based on RDMA vs one based on RPCs) performed better; I wrote a follow-up paper that organizes these optimizations as design guidelines for building fast networking software. All my graduate school papers have an abnormally large amount of hardware details and microbenchmarks, which often drew reviewer criticism that the work was more engineering and less research. In hindsight, the feedback was justified and useful because it forced me to distill and emphasize the new fundamental contributions in the papers.
RDMA in fall 2015: Hyperscale deployments and new applications
By the end of my second year, I was out of follow-up ideas. RDMA seemed like an unexciting research space to me because RDMA was still a niche HPC technology limited to InfiniBand clusters. InfiniBand has its own layer 2–4 protocols, which are incompatible with IP-over-Ethernet used in hyper-scale Internet datacenters. Deploying RDMA over Ethernet is challenging because RDMA NICs require a lossless link layer, which is baked into InfiniBand’s link layer, but not in IP-over-Ethernet networks. I started looking at other topics to build my dissertation on, like fast software packet processing for network functions.
My outlook changed in fall 2015, when Microsoft and Google reported their experience with making their huge datacenter networks lossless for RDMA by deploying Ethernet “pause frames” at scale. At around the same time, FaRM and DrTM showed how to use one-sided RDMA for a new high-value application: fast intra-datacenter distributed transactions. Suddenly, it was a great time to be an RDMA researcher.
Not a lost cause
After an internship observing teams at MSR Cambridge build production-quality systems, I was motivated to build a fast RPC library that developers could actually use, instead of building research prototypes. I was now starting my fourth year and had a number of publications, but the developers I talked to did not want to use the RPC libraries that I had built for HERD and later FaSST. The dealbreaker: my RPC libraries, similar to RDMA, depended on the network to prevent packet loss, and despite the progress in deploying lossless Ethernet at scale, such datacenters were rare. From a perspective of fundamental computer systems design principles, relying on in-network losslessness is misaligned with the end-to-end principle.
At the time, I did not think it would be possible to achieve high performance over lossy networks. While my RPC libraries and RDMA could achieve microsecond-scale latency and line-rate 100 Gbps bandwidth, I was convinced that the millisecond-scale timeouts needed for safely retransmitting lost packets would explode tail latencies and decimate throughput. Mittal et al.’s work on RDMA in lossy networks presented simulations that planted a seed of doubt in my head about my conviction.
One fortunate day, an unrelated email from another researcher made me realize that the Ethernet on the clusters that I had been using for my experiments was, counter to my assumption, not lossless. I had wrongly assumed that just because these clusters use Ethernet gear from Mellanox (a major InfiniBand vendor), they must be configured with pause frames by default. Without my knowledge, my RPCs had been working just fine on lossy Ethernet for years!
My experiments weren’t experiencing packet loss because today’s Ethernet datacenter switches have megabytes of buffer space, whereas RPC connections need to keep only kilobytes of data outstanding to get peak performance. These switch buffers prevent packet loss even during rare scenarios with hundreds of congested RPC flows.
eRPC: Efficient RPCs for Datacenter Networks
Our eRPC paper makes this insight concrete: We can prevent most packet losses by simply limiting the outstanding data on each connection to the network’s bandwidth-delay product. We add congestion control on top to further reduce the likelihood of packet loss. While prior solutions for high-speed datacenter networking usually rely on in-network features such as RDMA and link layer losslessness, eRPC follows an end-to-end design by implementing everything in end-host software, and demanding the bare minimum lossy packet I/O from the network hardware beneath.
At the end of my PhD, I had to some extent succeeded in building a fast RPC library that developers were interested in using. Today, several researchers use our eRPC code for their systems, and Intel uses it in their data acquisition database. Although eRPC builds on top of many research results, I could have in theory built eRPC in my first year. For several years, I mistakenly—but for good reason—believed that RDMA and/or lossless networks were necessary for good performance. I and other researchers did not consider end-to-end designs that do not rely on in-network support because we believed that such designs would not perform well, in part because we had not found all the required optimizations. In the end, we re-discovered an essential lesson from the end-to-end arguments paper: “Using performance to justify placing functions in a low-level subsystem must be done carefully. Sometimes, by examining the problem thoroughly, the same or better performance can be achieved at the high level.”
The road ahead: Fast networking for everyone
Despite the large amount of amazing research into high-speed networking and networked applications, most datacenter applications today still use slow communication with TCP/IP. These applications, including distributed databases and key-value stores, analytics systems, stream processing systems, and backends of online productivity software, are hungry for fast networking but there are no fast networking libraries that “just work”. Part of the problem is most applications today run on cloud virtual machines, whereas most research into fast networking software, including all my papers, assumes bare metal access, with notable exceptions from industry.
Researchers can address this problem by prioritizing reducing the barriers to entry for developers by minimizing both hardware constraints and code changes. I look forward to the progress in this exciting space.
Bio: Anuj Kalia is a Senior Researcher at Microsoft in the Azure for Operators team. His main interests are in high-performance networked systems.
Disclaimer: This post was written by Anuj Kalia for the SIGOPS blog. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent his employer.
Editor: Tianyin Xu, University of Illinois at Urbana-Champaign