

Editor’s notes: We invite SIGOPS award winners to write about backstories behind the award-winning work. In this article, Antonis Katsarakis shares the journey of his PhD dissertation–“Invalidation-Based Protocols for Replicated Datastores”–which received the Honorable Mention of the 2023 Roger Needham PhD Award. Antonis is now a Principal Researcher at Huawei Research. He received his PhD from the University of Edinburgh, advised by Professor Boris Grot, with coadvisors Vijay Nagarajan and Aleksandar Dragojevic.
Antonis wrote an incredible epic of the journey and we decide to publish it in a series of two articles.
Read the first article here: https://www.sigops.org/2024/thinking-outside-the-box-my-phd-odyssey-from-single-server-architecture-to-distributed-datastores/
We continue from Chapter II, Section III.
Section III: Tackling Datastore Challenges: Insights from Single-Server Architecture and Mythological Wisdom (Contd.)
[Stop 3] Zeus: Replicated and distributed locality-aware transactions
Challenge 3: An analogous story unfolds when considering transactions. State-of-the-art datastores that provide multi-object transactions with data availability deploy replication protocols, which statically shard data and cannot exploit the dynamically formed locality that exists in several transactional workloads. For example, many transactions in a cellular control plane involve one user repeatedly accessing the same set of objects (e.g., its nearest base station). Consequently, traditional protocols incur excessive remote accesses and numerous network round-trips to execute and commit each transaction on these workloads, hence curtailing the datastore’s performance.
Meanwhile, the opposite is true for strongly consistent transactions in the single-server multiprocessor. The multiprocessor’s transactional memory extends the invalidating coherence to afford transactions that dynamically exploit access locality to boost performance. For example, a core that has previously accessed and currently caches relevant data can perform a series of transactions on that data locally, eschewing remote access and coordination. Problematically, transactional memory is not resilient to faults, hence risking data availability.
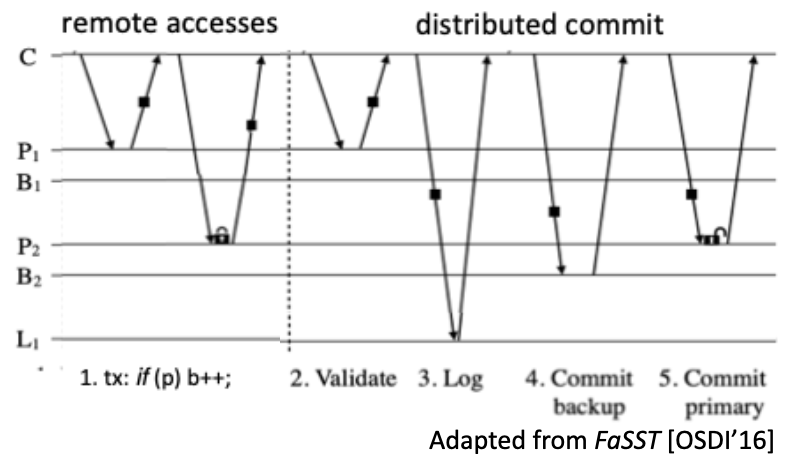
Solution 3: Inspired by the multiprocessor’s transactional memory, we propose and implement Zeus, a strongly consistent distributed transactional datastore that exploits and dynamically adapts to the locality of transactional workloads to maximize performance while also ensuring fault tolerance. To achieve this, we introduce two invalidation-based protocols. A reliable ownership protocol for dynamic data sharding that quickly alters replica placement and access levels across the replicas and a fault-tolerant transactional protocol for fast, pipelined, single-roundtrip reliable commit and local read-only transactions from all replicas.
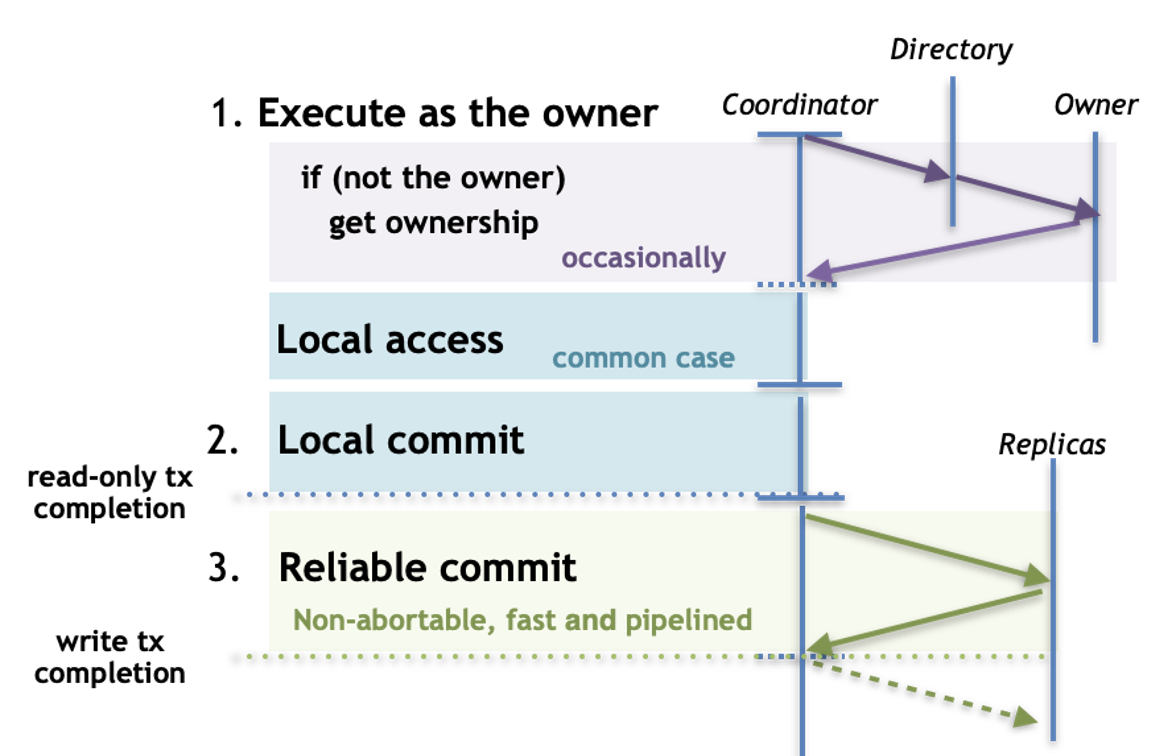
For workloads with data access locality, six Zeus servers can achieve tens of millions of fault-tolerant transactions per second and up to 2x the performance of state-of-the-art datastores while requiring less network bandwidth.
 | Mythology: Zeus datastore → Ownership and conflict resolution, mirroring Zeus’s control over his realm and mediation among gods. Insight: Single-server hardware transactional memory utilizes invalidations to exploit locality dynamically for efficient transactions by acquiring and maintaining ownership. Contrary to conventional wisdom: In the common case, where locality is captured, distributed transactions in Zeus execute locally and commit after a single round-trip with the strongest consistency and fault tolerance. Folklore to ignore: “Never write your own database” More info: [Eurosys’21], https://zeus-protocol.com |
[Stop 4] Themis’ L2AW of impossibility and almost-local reads.
Challenge 4: Fault-tolerant protocols can be synchronous or asynchronous, based on the model they rely on to ensure consistency. Synchronous protocols, which depend on bounded processing and communication delays, are easier to design. However, the network and compute nodes of a distributed datastore can experience timing anomalies (e.g., due to complex software stacks and virtualization layers), which may lead to timing violations and compromise the safety of synchronous protocols. To tolerate such timing violations, safer protocols adopt the asynchronous model where there are no timing assumptions (e.g., they do not rely on leases or global clocks), implying that processing and communication delays can be arbitrary.
Recall that datastores deploy fault-tolerant replication protocols that must offer high performance and strong consistency. As indicated previously, the performance of crash-tolerant protocols is highly determined by their ability to accommodate local reads. Thus, as other researchers also indicate (e.g., Schwarzmann and Hadjistasi), it is important to study the feasibility of crash-tolerant protocols capable of offering all three:
1) local reads; 2) strong consistency; and 3) safety under asynchrony.
Fundamental theoretical results related to asynchronous replication exist, including the FLP result and the CAP theorem. However, neither suffice to answer the above, as both fall short in examining the performance of reads.
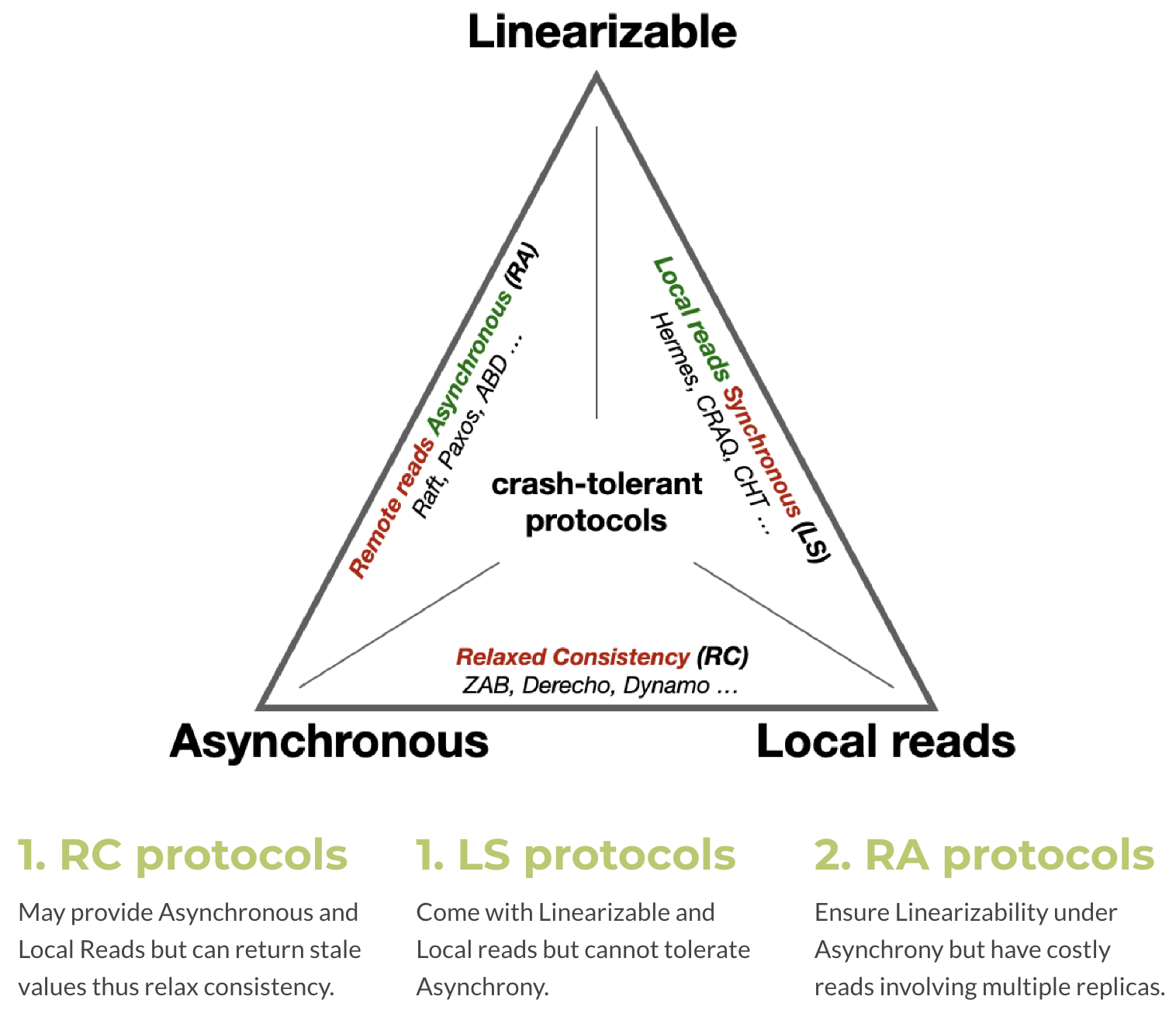
Solution 4 – Theory: We observed that existing crash-tolerant protocols sacrifice at least one of the three (local reads, asynchrony, strong consistency) and theoretically proved the L2AW theorem that no crash-tolerant protocol can provide all three—even before any crashes occur. More precisely, the L2AW impossibility asserts that: any Linearizable Asynchronous read/write register protocol that tolerates a single crash (Without blocking reads or writes), has no Local reads.
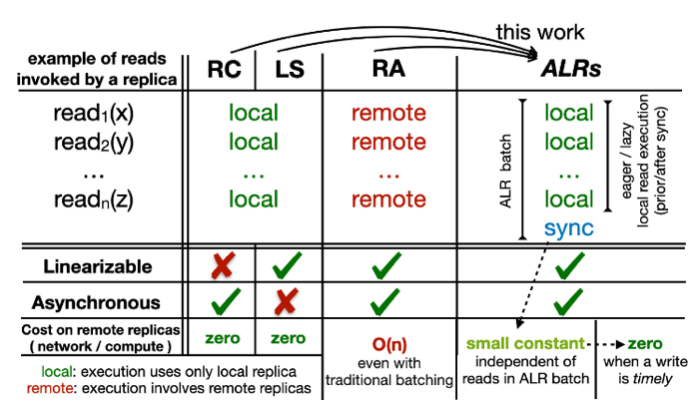
Solution 4 – Practice: Guided by this result, we introduce the practical idea of almost-local reads (ALRs), which can be implemented in a crash-tolerant and linearizable manner under asynchrony. ALRs exploit the high volume of concurrent reads in online services by leveraging batching, but with a twist. Unlike traditional batching, all reads in an ALR batch are executed against the local replica of a server, and only a lightweight sync operation per batch involves remote replicas. The sync incurs only a small constant network and computation cost, regardless of the batch size. Moreover, the sync is typically elided because existing writes can act as implicit syncs. As such, ALRs incur little or no extra network and processing costs to remote replicas, thus achieving the throughput of local reads while offering linearizability under asynchrony. Therefore, we demonstrate that the tradeoff exposed by L2AW affects mainly the latency and not the throughput of reads.
ARLs are general enough and can be applied to protocols in all three corners of the design space, adding the missing pieces: 1) improve throughput for protocols that sacrifice local reads; 2) ensure linearizability for protocols with weaker consistency; and 3) allow synchronous protocols to operate safely under asynchrony.
Our evaluation shows that ALR-enhanced invalidation-based protocols (e.g., Hermes) provide nearly identical throughput to the non-asynchronous variant, while also ensuring linearizability under asynchrony.
 | Mythology: Themis → As the Goddess of law and order imposes essential rules, the L2AW impossibility demonstrates a fundamental trade-off between consistency, asynchrony, and performance, defining the principles of crash-tolerant replication. Motivation: Can we implement fault-tolerant replication with strong consistency & local reads under asynchrony (e.g., via invalidations)? Contrary to conventional wisdom: It is impossible for crash-tolerant protocols to offer even a single strongly consistent local read under asynchrony. Yet they can provide almost-local reads, which inevitably have higher latency but as high throughput as local reads! Folklore to ignore: “Impossibilities indicate that you must stop trying.” More info: [Eurosys’23 – short], https://law-theorem.com/ |
Thesis Summary
Distributed replicated datastores powered by single-server-inspired ideas and invalidating protocols can deliver: strong consistency, load balance, fault tolerance, safety under asynchrony, and high performance (10s–100s M ops per second).
Chapter II: The 10 Tips
Herein, I share insights I would share with my younger self embarking on a PhD journey.
- Aim for “the ideal”
- Begin with the end in mind. What features does your ideal solution have? Go to the extreme of what’s feasible (e.g., 1 disk/memory access per request, 1 round-trip of replication, etc.). Then, work backward to make as much of this ideal a reality.
- Generate a plethora of ideas, no matter their absurdity or simplicity. Do not eagerly judge their merit. After cultivation time, reassess, refine, and combine the best.
- Shoot for the moon (10x, not 2x!)
Can you do 10x … Throughput? Power-efficiency? Capacity? Scale? Tail-latency?- 10x helps you to come up with radical designs, imaginative leaps, and rebel ideas.
- 2x traps you into incremental thinking; thus unlikely to get a substantial benefit.
- Question the conventional wisdom and Circumvent the impossible.
- Pursue things that are counterintuitive but true! Give special attention to paradoxes and things in which you disagree with conventional wisdom.
- Try to expose and exploit falsely believed tradeoffs.
- Study impossibility results, especially their assumptions and the boundaries in which they cease to hold. Always try to circumvent them. See which assumptions are unnecessary and would still be ok for the practical scenario you care about. For example, would CAP be equally applicable if you could leverage a wireless network?
- Nothing is entirely original: everything is a remix and the adjacent possible.
Others might disagree, but what is “novel” is quite a philosophical question. A lot (most?) of the ideas are just a remix of existing ideas. I highly recommend also understanding the meta-idea of the adjacent possible. Steven Johnson described it well: “The adjacent possible is a kind of shadow future, hovering on the edges of the present state of things, a map of all the ways in which the present can reinvent itself.” - Metaphors, Exaptation, and Blending
- Several communities that primarily work in isolation see the same or similar problems from different angles. Find problems similar (in some way) to yours from distant fields. How are those solved? Can you get any inspiration?
- Exapt things originally conceived for another problem to solve yours. Do you still have second thoughts? That’s how nature learned to fly.
- Combine, breed, juxtapose, and cross-pollinate ideas across fields, theory and practice, hardware and software, art and science.
- Exploit emerging hardware
- A very common way of publishing papers in systems is “redesigning X” for the new shiny hardware Y. Recently, thanks to the AI boom, new (highly capable) hardware has emerged rapidly (1000 Gbit NICs, 1000s of cores, Terabytes of Memory, HBM, CXL, etc.). How would you redesign systems (not just for AI) to fully exploit this hardware?
- New hardware may also blur the lines between fields and thus enable further cross-pollination of ideas between different communities (e.g., HPC and databases, or architecture and systems—as we previously discussed).
- Keep it lean
- What survives is the simple that gives 80% of the benefits.
- Follow the 80-20% rule: cut 80% of crap to simplify your work after each iteration
- In retrospect, good ideas are simple and seem obvious.
- Yet, they pack tons of meaning in a little bit of messaging.
- Pre-think, Read, and Don’t put people on a pedestal.
- Think before you read: To avoid being biased, postpone looking at existing solutions (e.g., papers) for problems you would like to solve. First, try to come up with a reasonably good idea, and then go through related work.
- Learn from the best in your field. However, it does not matter if you are not called Hallerstein, Osterholt, Pavlov, Liskott, Belkrishna, Limport, or whatnot; You can always come up with equally good or better ideas! You just have to put in the effort.
- The best thing I did during my PhD was reading non-CS books. Prime yourself with a book relevant to a task you want to accomplish (e.g., writing, problem-solving, etc.). Some non-CS book recommendations (ask me for more):
- Where good ideas come from [ideas]
- Stylish academic writing [writing]
- Ted talks: the official TED guide to public speaking [presentations]
- Rejection leads to improvement.
- Decouple your ideas and writings from yourself. After all, 20% acceptance means that most papers are rejected.
- Have a strong stomach and perseverance. It is not just you; the paper I am most excited about has been rejected five times so far. 🙂
- Rejection may mean you are on to something; you just need a bit of calibration.
- Embrace the journey
- Have fun. Be playful, like a child. Pick a theme in your work and draw parallels outside your research field (e.g., see mythology in my case). Ask smart-dump questions. Tinker with prior art. Be the wise fool.
- Combine things you enjoy. A PhD might be about depth on a single subject, but don’t be boring. Give yourself some breadth, diversify, and explore new things.
- Travel, go to conferences, do internships, and network a lot.
Bonus. Remember your Fundies
Last but not least, do not forget the fundamentals:
- Sleep well.
- Get sun exposure.
- It is always better with friends and your loved ones.
- Connect with nature, do your hobbies, walk, exercise, meditate …
Chapter III: A Rhymed Summary
Thesis
Servers as systems, blurred lines convey,
A single server’s facade, we overlay.
Thinking deep inside the box, we say,
Challenging norms, with questions, we weigh.
Look-alike mechanisms, in our survey.
Replication, caching, in metaphor’s sway.
Protocols invalidating, a new pathway,
Between theory and practice, we overlay.
Tips
Aim for the moon, let not folklore sway.
Architecture and systems, in unison, may.
The impossible, we cleverly parlay.
AI’s revolution, a hardware display.
Books and ideas, our paths pave,
Dream big, 10x, without delay.
Ideas cross-pollinate, in a vibrant fray,
Lean into simplicity, our ultimate play.
Call to action
One day, power and scale will find their way,
One day, memory’s limits, we’ll boldly fray,
One day, trees will be speedy, no delay,
What are you doing now, to bring that day?
One day, server or systems, same we say,
One day, links, partitions will fade away,
One day, CAP’s rules we won’t obey,
One day, soon here, not far away.
So, what are you doing that day?

Editor: Tianyin Xu (UIUC) and Dong Du (Shanghai Jiao Tong University)