

Editors’ note: LDOS (Learning Directed Operating System) is among the most exciting expedition projects that showcase how AI could help revamp policies and mechanisms of modern operating systems (arguably the most important systems software). In this article (the fifth blog in The Next Horizon of System Intelligence series), the LDOS team shares their vision, roadmap, and recent work, offering many new insights and perspectives of OS research in the AI era.
Operating systems (OSes) form the backbone of nearly every computing platform, from smartphones and personal robots to cloud servers and mobile access edges. Yet, despite advancements in hardware and applications, the OS has seen relatively few transformative innovations since the 90s, a critique popularized in Rob Pike’s slides on irrelevant systems research. Many core OS subsystems still reflect this conservatism – the latest Linux kernel continues to rely on a CPU scheduling algorithm that was first proposed in 1995; its networking stack still defaults to CUBIC congestion control, adopted 20 years ago; and its memory management subsystem retains legacy data structures, abstractions, and policies, even as modern memory architectures have evolved rapidly.
Meanwhile, the world around the OS has changed dramatically. Applications are increasingly diverse and latency-sensitive, and hardware has become far more heterogeneous. In this setting, long-standing OS policies and hand-tuned heuristics are starting to fall short. Recent work shows that the Linux kernel may waste seconds allocating hugepages that don’t pay off (Mansi et al., 2022), or may starve bandwidth (Arun et al., 2022), or may idle cores despite having runnable tasks (Lozi et al., 2016). These failures share a common root cause: existing OS policies are rigid. They encode assumptions about workloads, hardware, and contention that were reasonable when they were designed but no longer hold across today’s rapidly changing environments.
This raises a natural question: Could an OS do better if its policies could adapt, tailoring themselves to workloads and environment? What would such an adaptive OS look like? We believe recent advances in machine learning make it possible to fundamentally rethink OS design around adaptivity. Our vision is to build Learning Directed Operating System (LDOS), an intelligent, self-adaptive operating system that uses learned policies to share resources efficiently and effectively, enabling capabilities that would otherwise require prohibitive overprovisioning or extensive but ultimately futile human tuning. By moving beyond static heuristics, LDOS can tackle long-standing challenges in domains such as robotics, datacenters, and the mobile edge, where reliable performance comes at high overall system cost (e.g., less than 10% utilization in the public cloud) or substantial manual engineering and management effort.
This blog post introduces the motivation for LDOS, trade-offs of learned OS policies, and the roadmap we are pursuing as part of the LDOS NSF Expeditions project, conducted by researchers at the University of Texas at Austin, University of Pennsylvania, University of Wisconsin-Madison, and University of Illinois at Urbana-Champaign.
Where do current Operating Systems fall short?
At their core, operating systems allow multiple applications to run concurrently by coordinating access to shared resources such as CPU, memory, and the network. However, modern applications are very heterogeneous – placing diverse requirements on these resources and on performance metrics such as latency and throughput. Unfortunately, resource management in today’s OSes is fundamentally ill-suited to these demands. Even when resources are sufficient, OSes could struggle to provide dependable performance under contention.
Consider consumer robots (see Fig. 1): while the OS can often run core applications like navigation reliably in isolation, performance degrades sharply once third-party or auxiliary applications are introduced, despite ample hardware resources. Solving this problem today requires developers to carefully set scheduling priorities and deadlines – a tedious, error-prone process that breaks down under unpredictable compute demand from third-party applications.


Fig. 1: (left) when only the navigation app is running, and (right) when an object detection app is launched alongside navigation. In the latter case, the OS onboard the robot misses scheduling deadlines required by the navigation controller, causing it to fail catastrophically. (see ConfigBot for more details)
Similar issues arise in multi-tenant cloud and edge platforms, where dynamically changing workloads make it hard for OSes to provide dependable, real-time performance to co-located applications. The usual workaround is to overprovision – but this is wasteful, expensive, and often infeasible. In multi-tenant clouds, overprovisioning already drives utilization as low as 10%, an approach that is simply untenable going forward.
The root of this problem lies in how today’s OS policies are structured: they make local decisions using fixed algorithms or heuristics. This policy architecture has three fundamental drawbacks.
Flaw 1. Policies’ decision-making is rigid and limited. Existing policies employ heuristics with fixed logic that bake in assumptions. When those assumptions break because the workload mix changes or because new applications behave differently, these rigid policies have no principled way to adapt. As a result, decisions that are reasonable under expected conditions become suboptimal in complex or dynamic settings, such as a robot operating in a cluttered, unpredictable environment or in the presence of other contending applications.
Flaw 2. Policies are not designed to compose. Today’s OS policies make decisions in isolation: each subsystem (CPU, memory, network) makes fast, local decisions based on its own counters and objectives. These policies fail to coordinate with one another, degrading end-to-end performance. For example, in the Linux memory subsystem, the memory deduplication policy (KSM) does not consider AutoNUMA’s placement strategies and may place merged pages on the wrong NUMA node, leading to performance degradation. Such non-coordinated policy decisions are common across the kernel.
Flaw 3. Policies are enmeshed with mechanisms. Policy-mechanism entanglement in today’s OS implies that interesting data that can drive useful decisions is strewn across subsystems hidden behind interfaces and within function calls. This makes it difficult to collect rich data in a principled way, and it discourages policies from incorporating it. For instance, the CPU scheduler today does not use metrics from the I/O or networking subsystems – leading to wasted CPU cycles when tasks stall on I/O or wait for network events.
Learned Policies: The Pros and Cons
Ideally, we would like policies that make coordinated decisions that adapt based on diverse telemetry available in the OS. Learning – in particular, deep learning – has proven to be a promising tool in dealing with dynamic environments and outperforming human-designed heuristics in several other domains, such as query optimization, indexing, and traffic engineering. This success stems from the ability of learning algorithms to use a wide variety of features, predict future behaviors accurately, and tailor decisions to each context better than human-crafted generic heuristics. These same strengths make ML a natural fit for operating systems: learning can convert rich OS telemetry into coordinated, adaptive decisions.
However, learning-based policies in the OS are not without their challenges.
Challenge 1. Learned policies are data-hungry. LDOS policies demand large amounts of data on applications – their inputs, resource demands, and the surrounding environment – for effective training. Collecting such multivariate time-series data at a high cadence from live systems can be challenging due to the volume and overhead.
Challenge 2. The cost of an incorrect decision. Learning algorithms optimize a statistical loss function, but it may not always be feasible to capture all undesirable system states in a simple function. Moreover, deep learning rarely guarantees global optimality, leaving inputs where learned policies can still behave suboptimally. Unlike conventional uses of learned systems (e.g., in a chatbot) – where humans can often recognize and correct inaccurate responses – incorrect decisions by OS components in the fast path can be hard to detect and catastrophic.
Challenge 3. Overheads of learned policies. Running a learned policy could incur performance overheads, e.g., collecting features from a live system, performing model inference on the critical path, or online training of the model. If the overheads overshadow the benefits of an improved policy, the overall performance will still regress or end-to-end efficiency will be hurt.
The LDOS way: A clean-slate design
We believe that by addressing the architectural flaws of today’s OS design and rethinking how learned policies operate in the OS context, we can make LDOS a practical reality. Fig. 2 shows our vision for LDOS at a high level. First, ML-driven policies in LDOS are trained offline using data about workloads and system environments. This data can either be generated or augmented using synthetic data generators to obtain high-quality training data. Then, the trained ML policies are deployed to the LDOS kernel zero-touch, i.e., without needing an OS reboot. Once policies are deployed, LDOS monitors the decisions to ensure the policies are meeting apps’ estimated needs, using built-in introspection. If not, LDOS automatically adapts by retraining offline and updating the models.
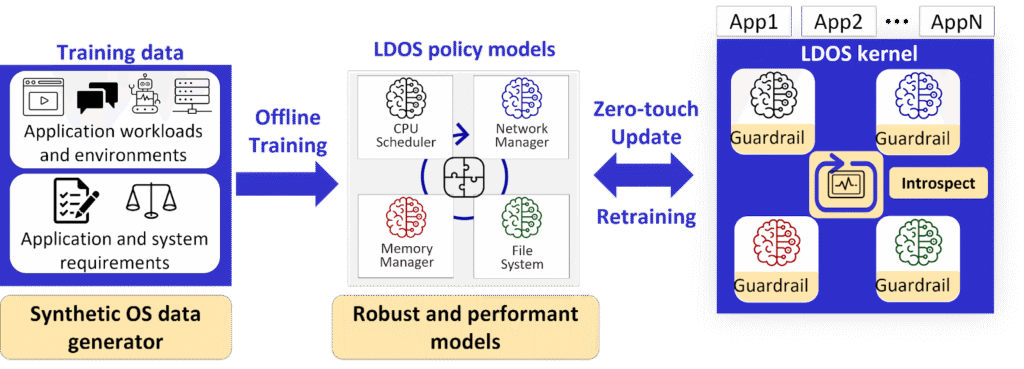
Fig. 2: Clean-slate design for LDOS.
However, realizing this LDOS-style policy development in today’s OSes is close to impossible. As we mentioned before, policies and mechanisms are deeply entangled and necessary features are strewn across subsystems: consider the Linux kernel “map” (Fig. 3) showing abstraction layers and resources. Resource management heuristics use features such as component-specific counters, and they are dispersed throughout (shown by dashed ellipses). Similarly, policies (in solid ellipses) are widely dispersed and uncoordinated. This structure is a major obstacle to implementing, training, and deploying learned policies. This calls for a paradigm shift with a new OS structure where adaptable ML-driven policy is the primary concern: the OS design must enable policies to be auto-generated and efficiently leverage global system state to make better-informed decisions.
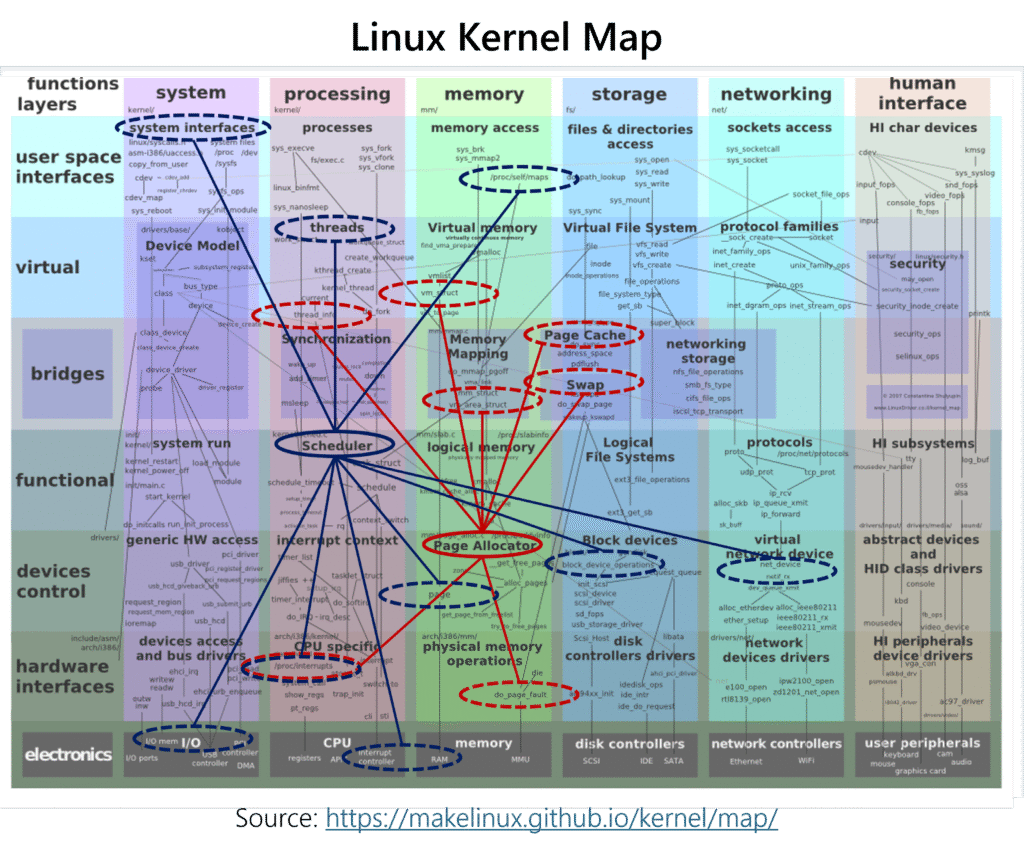
Fig. 3: The Linux kernel map: the red “graph” shows a subset of features useful for hugepage allocation policy, and the blue “graph” shows a subset of features useful for the CPU scheduling policy: Features cross subsystem and abstraction boundaries, and can also be shared between multiple policies!
The Roadmap to LDOS
Realizing the LDOS vision is far from straightforward – we believe it requires tackling several challenging and exciting problems. Below, we identify four key research directions in this space, each informed by concrete studies from our work so far.
Research Direction 1: Synthetic data generation
Collecting high-quality data can impose instrumentation and data collection overheads. Thus, we must supplement data collected at low overheads with synthetic data that is realistic yet diverse enough. Our vision is to develop generative models for systems data that will be used as foundation models for various LDOS training and inference tasks. We have found that existing LLMs are not sufficient to generate data with the fidelity and diversity required for systems traces, thus requiring novel pre-training and fine-tuning techniques for the foundation models we desire. Our first steps in this direction have resulted in a new trace generation LLM for microservice call traces (TraceLLM, EMNLP 2025).
Research Direction 2: Composable and verified policies
As discussed above, incorrect decisions by OS sub-systems can lead to sub-optimal performance or catastrophic behavior. This calls for techniques to verify that decisions from learned OS policies are not poor – essentially requiring integration of learning with verification. This is a rich direction of research, especially as we scale this to complex compositions of learned models and human-engineered code. We have already developed techniques to do this for learned congestion and microservice controllers, where we employ formal verifiers and domain-specific analytical models to provide useful feedback during training (Canopy, EuroSys 2026; Galileo, NSDI 2026).
A related challenge is to train multiple policies that provide good end-to-end behavior. We term these policies to be composable. This requirement stems from the fact that OS policies are hardly independent – they rely on inputs from other policies or work together to provide some end-to-end subsystem-level feature. Our proposal is to use representations of shared features, states, and decisions to learn composable policies. We have seen success for this approach, especially for the network stack, where we built and used a common encoder across multiple controllers, such as congestion control and ABR. (UNUM, NSDI 2026)
Research Direction 3: Integrating ML policies into the OS
LDOS policies need to be deployed in the OS kernel – this imposes novel requirements on OS design. We need new OS abstractions, interfaces, and workflows that enable easy implementation and integration of learned OS policies. Just as MLOps and DevOps streamline workflows for ML developers and software engineers, we need a Kernel MLOps pipeline: a precise kernel interface for feature collection, rapid iteration over model architectures, and principled deployment of learned kernel policies (LAKE, ASPLOS 2023). Simultaneously, we need new OS dataplane mechanisms to efficiently support adaptation while requiring minimal human intervention. For instance, to achieve self-introspection for OS policies, we need run-time monitors that can track performance- and safety-related properties and enable adaptation within the kernel (Guardrails, HotOS 2025).
Research Direction 4: Implementing a clean-slate LDOS
Deploying learning policies in the OS is a critical step, especially as the LDOS vision involves switching policies in response to changes in the workload or environment. While systems such as sched_ext and cache_ext enable extensible policies for individual subsystems, they still lack flexibility: there is no unified mechanism for replacing arbitrary OS policies, and policy replacement today requires tedious code changes and plumbing. Solving these problems requires redesigning how policies are deployed in the OS and how the OS exposes replaceable policies to userspace. Thus, we hold the ambitious goal of building a clean-slate OS that is built to be learning-directed.
While our ultimate goal is a clean-slate data-driven kernel, we are also working on libraries and policies that bring data-driven decisions to Linux. The steps we outline toward LDOS are not just about building a new OS – they offer practical benefits for the broader OS community. For example, realistic synthetic data for training OS policies is broadly useful across systems, and methods for learning, composing, and deploying verified policies can inform policy development in any OS.
Harnessing advances in ML techniques for LDOS
The research directions outlined above complement recent advances in machine learning, including LLM-generated systems (as alluded to in previous blogposts) and LLM-driven evolutionary search (FunSearch, AlphaEvolve, etc.). We believe these advances can address some key limitations of traditional ML approaches in systems – particularly the overhead of deploying learned policies and the difficulty of refining them under changing contexts. For example, generating specialized “learned” code via LLMs in LDOS can eliminate runtime inference overhead. Likewise, the ability of LLMs to ingest natural language feedback opens new avenues for policy refinement.
Yet fundamental challenges in the OS policy architecture remain, requiring principled integration of LLM capabilities with foundational LDOS research. This raises several key questions: How do we construct diverse and representative training data for LLM-driven evolution? How do we provide precise natural language feedback to produce composable policies? And how do we prevent catastrophic outcomes from decisions produced by LLM-driven policies?
We have started looking at some of these questions with the LDOS lens and found both promising results and new challenges that LLM-driven policies impose (PolicySmith, HotNets 2025). Stay tuned for future blog posts as we delve deeper into these techniques and the ensuing challenges!
Learning more about LDOS
This blogpost represents work done by the broader LDOS team. We have ongoing projects across each of the thrusts above, and in our future communications, we hope to provide a more in-depth look at our progress and share the insights we’ve gathered. Meanwhile, we invite you to take a look at published work, visit our website at ldos.utexas.edu, and connect with us on LinkedIn to see past and future updates about the work we’re doing.
This article is edited by Mike Chieh-Jan Liang, Haoran Qiu, and Tianyin Xu.