

Editors’ note: Self-Defining Systems is a new paradigm and a new research initiative at the University of Washington with the goal of leveraging the unique abilities of LLMs to accelerate infrastructure agility, while compensating and masking their weaknesses. It envisions a future in which infrastructure can design, validate, and evolve itself with minimal human intervention. In this article (the sixth blog in The Next Horizon of System Intelligence series), the SDS team shares one concretization of SDS – the Self-Defining Operator – for autonomously managing complex applications, including its early results and open research challenges.
AI agents that autonomously resolve operational issues enable faster production incident response, reduce engineering burden, and address service degradations before they escalate. Today’s LLM-based agents can diagnose production incidents and propose fixes, but each session starts from scratch. If the same failure recurs, a new agent must rediscover the root cause. A core part of our research agenda, Self-Defining Systems (SDS), is to move beyond fixing isolated incidents to keeping systems healthy over time, paving the road towards end-to-end system design and operation (whitepaper). This post focuses on the operational side: taking applications from source code to production and keeping them healthy over time.
To see what today’s agents are missing, consider how experienced operators work: they carry a mental model of the system’s layout and vulnerabilities, built from years of diagnosing failures, and use that knowledge to resolve production issues quickly. Agents lack deployment-specific context: the topology of this application, its prior incidents, and its idiosyncratic failure modes. As a result, the mean time to resolution (MTTR) remains unchanged regardless of how many incidents they have handled on the same deployment. Closing this experience gap requires maintaining memory across sessions, an idea well-studied in conversational AI and retrieval-augmented generation. Applying it to system operation poses additional challenges: operational knowledge must be grounded in a specific deployment’s topology and failure history, and agents must distill raw traces into reusable patterns and expire stale entries as the system evolves.
Prior Work: Agents that Reason Well but Forget Past Experiences
Two design patterns dominate recent AI-for-systems work, both effective within a single session but unable to learn across sessions. Evolutionary approaches, pioneered by AlphaEvolve and applied to systems problems (as discussed in a recent SIGOPS post), use LLMs to iteratively generate and evaluate candidate algorithms, often outperforming hand-tuned baselines. However, the output is an optimized artifact, not reusable knowledge about why certain designs work. Multi-agent approaches like Glia and Stratus assign specialized roles (e.g., proposer, critic, evaluator) so that agents collaboratively refine designs or diagnose faults. But they encode expertise in role prompts and coordinate within a single session, with no mechanism to carry lessons forward. Both patterns start each new task from scratch.
The Self-Defining Operator
We are building the Self-Defining Operator (SDO), a multi-agent system with long-term memory that operates complex applications autonomously. Unlike fault-diagnosis systems like Stratus that assume an already-running deployment, SDO takes full application source code from initial deployment to ongoing operation. We initially target microservice applications on Kubernetes: inter-service interactions create emergent, deployment-specific failure modes that can benefit from past knowledge.
SDO treats both undeployed and failing applications as unhealthy and follows the same phased workflow to drive each toward a healthy state (Figure 1). Rather than keeping a single long-running agent session alive, which inevitably hits context window limits and forces lossy summarization, the Operator starts a fresh session at every phase transition and agent handoff. Continuity comes instead from a shared knowledge base (detailed in the Knowledge Base section below): a persistent file tree containing an architectural summary of the application, a long-term operations summary consolidating all prior incidents, and per-incident post-mortems recording symptoms, root causes, and fixes. Agents read from this knowledge base at any point during a session and write back upon resolving an issue.
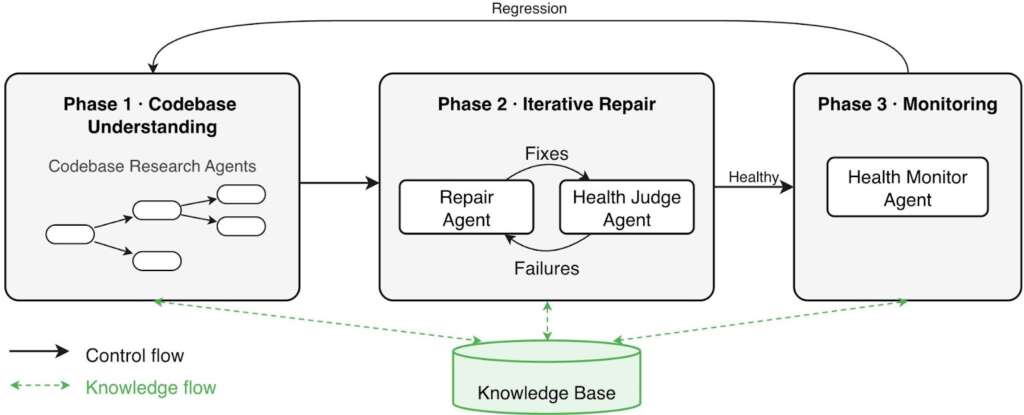
Workflow
The workflow separates read-only analysis (Phase 1) from repair (Phase 2) and continuous monitoring (Phase 3). This ensures agents build a thorough codebase model before attempting changes, prevents the repairer from evaluating its own output, and decouples monitoring from episodic repair.
Phase 1: Codebase understanding. Agents traverse the codebase and construct the architectural summary. For large codebases, an agent spawns subagents to research sub-components in parallel, consolidating findings into the architecture document.
Phase 2: Iterative repair. A repair agent and a health judge agent drive the system toward a healthy state through a hypothesize-evaluate-revise loop. The repair agent proposes a fix; the health judge validates the result by checking liveness probes and running end-to-end tests derived from the architectural summary, writing tests if none exist. If the system remains unhealthy, the health judge summarizes what was tried and what remains broken. A fresh repair agent then starts from previous iteration summaries and consults full logs only when it needs deeper context. On resolution, the health judge synthesizes a post-mortem and updates the operations summary. Fixes may touch deployment manifests, configuration, or application code.
Phase 3: Monitoring. Once the application is healthy, a monitor agent watches health signals for regressions. On failure, the system loops back to Phase 1. Agents use the architectural summary and prior post-mortems to ground the failure in application context and begin with a localized fault hypothesis rather than undirected exploration. Each resolved regression produces a post-mortem and updates the operations summary.
Knowledge Base
The knowledge base decouples retention from any single session. Stored as a persistent file tree rather than in-context history, the knowledge base enables progressive context disclosure: agents start each session with the architectural summary and the operations summary, then pull in post-mortems and finer-grained records on demand. As incidents accumulate, agents distill individual post-mortems into higher-level patterns in the operations summary: for instance, a post-mortem recording “service X crashed because MongoDB’s port was misconfigured” contributes to a summary-level pattern like “services often fail due to incorrect connection endpoints; verify ports and hostnames against the deployment manifest.” Because many incidents share root causes, the summary remains concise and fits within the context window even as post-mortems multiply. Unlike agent instruction files and skills that give agents static, human-curated context, the knowledge base is written and maintained by agents themselves, growing as they resolve incidents. It also doubles as a shared artifact between agents and operators, giving operators visibility into what the agent has learned and the ability to inject corrections.
When a failure occurs, an agent can match it against prior root causes and resolution strategies in the knowledge base, then validate whether any apply to the current incident. Without this context, the agent must explore from scratch.
Early Results: The Benefits of Accumulating Knowledge
We evaluate SDO on 11 microservice applications commonly used in systems research and on the SREGym benchmark for fault diagnosis and mitigation.
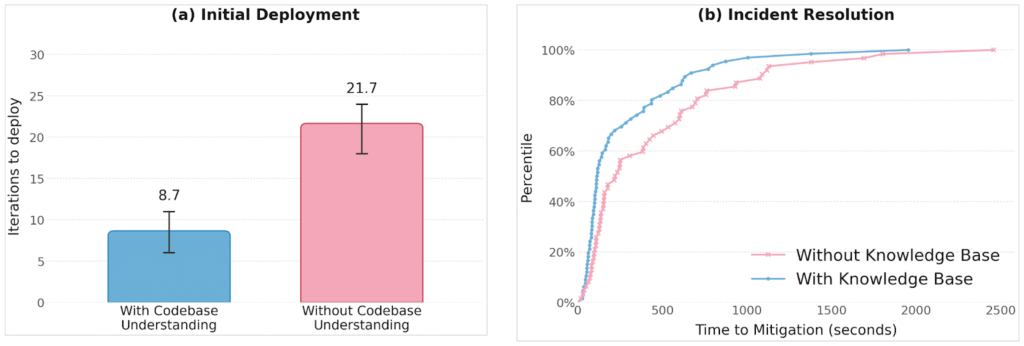
Architectural context cuts time to deployment. Comparing the Operator with and without the codebase understanding phase (Phase 1), we find that architectural context reduces iterations to successful deployment by 2.5x (Figure 2a). Without it, agents default to local reasoning, addressing each service’s errors in isolation without considering how fixes affect the services that depend on it, leading to cascading repair attempts that eventually converge but require significantly more iterations.
Building experience cuts time to failure mitigation. Many deployment failures share root causes: misconfigured environment variables, implicit dependency ordering, startup race conditions. When agents have resolved similar failures before and recorded them as post-mortems, they can match incoming symptoms to prior root causes and skip unsuccessful repair strategies. On SREGym, seeding the knowledge base with post-mortems from a prior run yields a 38% reduction in MTTR (Figure 2b).
Open Research Challenges
Bootstrapping operational expertise. When SDO is first deployed on a real application, its knowledge base starts empty, so early incidents pay the full cost of exploration. We are exploring a chaos-engineering-inspired approach to accelerate this: a chaos agent reads the application’s source code and configuration, then mutates them to introduce deployment failures. Because the chaos agent authored each mutation, it also knows the correct fix, effectively generating labeled evaluation scenarios. SDO resolves these manufactured failures and accumulates knowledge before facing real production incidents.
Knowledge staleness. Operational knowledge can silently become stale. A post-mortem recording “service X crashes without environment variable Y” is useful until a refactor removes that dependency. If the agent still consults this entry, it wastes time on a phantom cause—or worse, reintroduces a now-unnecessary configuration. Agents need mechanisms to track validity conditions and expire entries when the system changes.
Cross-application knowledge transfer. Knowledge compounds within a single application. Does it transfer across applications? Within an organization, applications share code, libraries, and services, so a failure mode in a shared library or a misconfiguration in a common service likely recurs across applications. An agent that has already diagnosed such a failure in one application holds knowledge that no training data can provide, since it is specific to the organization’s internal codebase. Transferring that knowledge to other applications that share the same components is an opportunity to accelerate resolution without rediscovering the same lessons. But surface similarities can mislead: what looks like the same problem in a different topology may require a different fix. Determining which operational lessons transfer safely remains open.
Alignment with developer intent. The Operator occasionally resolves failures by violating implicit constraints, such as relaxing a resource limit rather than addressing a memory leak. Stratus addresses this reactively through rollback-ability analysis, but some violations are dangerous: disabling authentication, even briefly, can expose data that no rollback recovers. We are exploring automated test hardening, where agents codify implicit assumptions as tests, but fully capturing developer intent remains a fundamental limitation: implicit constraints are rarely specified fully and cannot be exhaustively recovered from code.
Looking Ahead
Our work suggests that the operational tier of the SDS vision is realizable today: agents can understand complex distributed applications, deploy and keep them operational through structured failure-recovery loops, and build operational knowledge that compounds across incidents.
The broader opportunity lies in closing the loop between operation and design. If agents repeatedly encounter the same class of failure across deployments, that signal should flow upstream and inform architectural decisions that prevent it. We outline this broader vision in our whitepaper.
We are grateful to the undergraduate researchers who helped build and evaluate the SDO prototype and contributed ideas for future directions: Vinamra Agarwal, Soham Bhosale, Tarang Dalela, Noah Hoang, Aidan Liu, Liander Rainbolt, Khoa Vo, and Daniel Zhang.
Editors: Francis Yan, Haoran Qiu, and Tianyin Xu