

Editor’s notes: We invite SIGOPS award winners to write about backstories behind the award-winning work. In this article, Antonis Katsarakis shares the journey of his PhD dissertation–“Invalidation-Based Protocols for Replicated Datastores”–which received the Honorable Mention of the 2023 Roger Needham PhD Award. Antonis is now a Principal Researcher at Huawei Research. He received his PhD from the University of Edinburgh, advised by Professor Boris Grot, with coadvisors Vijay Nagarajan and Aleksandar Dragojevic.
Antonis wrote an incredible epic of the journey and we decide to publish it in a series of two articles.
Chapter I: The Odyssey
As I embarked on my PhD journey, little did I know that single-server architecture and ancient mythological wisdom would illuminate the path to modern distributed datastores with:
- High performance under strong consistency despite aggressive replication.
- Fault-tolerant protocols that are significantly faster than Paxos.
- Reliable distributed transactions that commit after just a single roundtrip.
- Ultra-high throughput while tolerating asynchrony.
Section I: Leaving Ithaca
I still vividly remember the sleepless nights I spent composing my PhD proposal during the hot Greek summer of 2016. Back then, my future-telling advisor (Boris Grot) charmed me with the potential of Rack-scale Interconnects and Disaggregated Memory, which enticed me to move to Edinburgh and shaped my research proposal.
When I ultimately joined the University of Edinburgh, I met my second advisor (Vijay Nagarajan), who also had a recently starting student (Vasilis Gavrielatos). Almost immediately, the four of us began collaborating* on the topic of distributed in-memory datastores interconnected over Remote Direct Memory Access (RDMA) networks.
Although distributed datastores, such as key-value stores and databases, were not precisely the topic of my initial proposal, they were fascinating as they combined all the subjects I enjoyed the most since my excellent undergrad studies (at the University of Crete), from algorithms and distributed systems to databases and networking, but perhaps most surprisingly, computer architecture.
*Disclaimer: This and other fruitful collaborations with academics (P. Bhatotia from TUM and P. Faturu from the University of Crete) and industrial researchers (A. Dragojevic, B. Radunovic, and M. Castro from Microsoft) propelled my work. Hence, do not be fooled! The content described next is by no means a solo endeavor, irrespective of the pronouns used.
Section II: Single-server vs Distributed Computing: the parallels and the dichotomy of fast or fault-tolerant replication
Today’s most popular applications, including social networks, telecommunications, and financial services, rely on datastores to store their ever-growing data. Datastores split and store application data across a cluster of servers. As modern applications have numerous concurrent users who generate data requests, datastores must deliver high performance. For performance, datastores replicate application data across multiple servers. Replication also ensures that data remain accessible in the face of server crashes and other faults.

Datastores deploy replication protocols to keep the data replicas synchronized and provide the illusion of a single copy (i.e., strong consistency), even when faults occur. To achieve this, replication protocols define the exact actions required to access and update the data. Thus, in addition to guaranteeing strong consistency and the ability to endure faults, replication protocols also determine the performance of a datastore. Problematically, existing replication protocols deployed by datastores fall short in terms of performance.
Solving problems in the distributed domain fundamentally requires out-of-the-box thinking. At first glance, the work of my thesis achieves this unconventionally by looking deeper and getting inspiration from inside the single-server box and its architecture.
This should come as no surprise to those realizing how blurry the lines are between modern distributed and single-server computing. Modern distributed computing is enhanced with RDMA and other emerging interconnects (e.g., CXL), which enable access to far memory that supports pooling and even shared coherent remote accesses. From this perspective, a modern server rack or cluster looks like a large single-server (multiprocessor).
Similarly, a modern server architecture resembles a distributed system, equipped with all kinds of NUMA socket configurations, lots of different types of compute (heterogeneous CPUs, DPU, GPU, accelerators), and various memory technologies (DDR, PMEM, HBM, PIM, NVMe, etc.).
Adding to this parallel, protocols for strong consistency are also well established when data are replicated across different memories inside a single-server multiprocessor. Protocols in the multiprocessor context synchronize replicas using invalidations to deliver high performance but cannot tolerate failures.
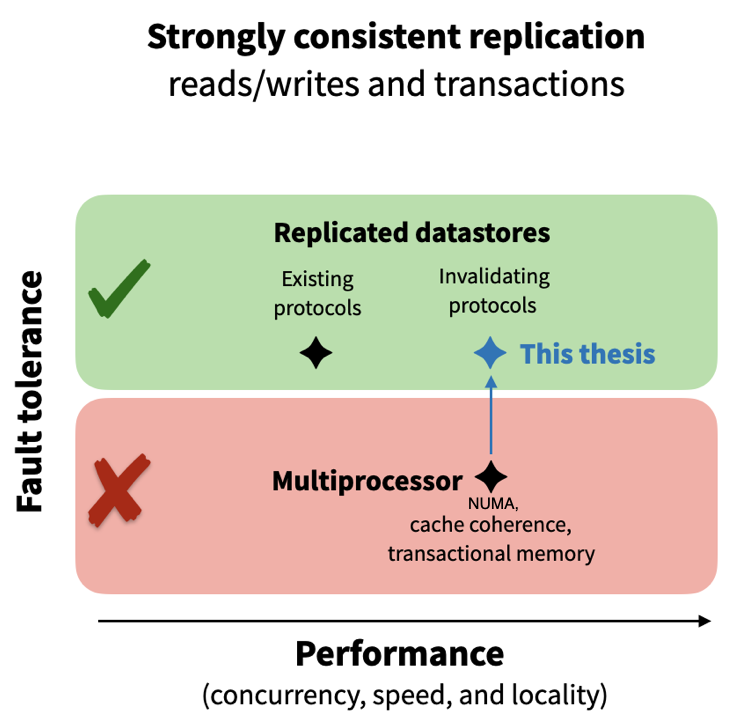
A key observation of my thesis is that the common operation of replication protocols in datastores does not involve faults closely resembling the multiprocessor setting. Based on this insight and the above parallels, we take inspiration and adapt ideas from single-server architecture (including NUMA, coherence, and hardware transactional memory) to distributed replicated datastores. The central theme is invalidating-based replication protocols. We introduce four invalidating protocols and advance the state of affairs in strongly consistent replication by exploring load balance, performance, fault tolerance, transactions, and asynchrony, as we describe next.
Section III: Tackling Datastore Challenges: Insights from Single-Server Architecture and Mythological Wisdom
[Stop 1] Load balance via Symmetric caching and Galene’s timestamped invalidations
Challenge 1: Data access skew is a prevalent workload characteristic of online services, including search and social networks. In short, a small number of data objects are drastically more popular and likely to be accessed than the rest. Thus, the datastore servers holding these hot objects are overloaded while the majority of servers remain underutilized. Problematically, the resulting load imbalances inhibit the datastore’s performance.
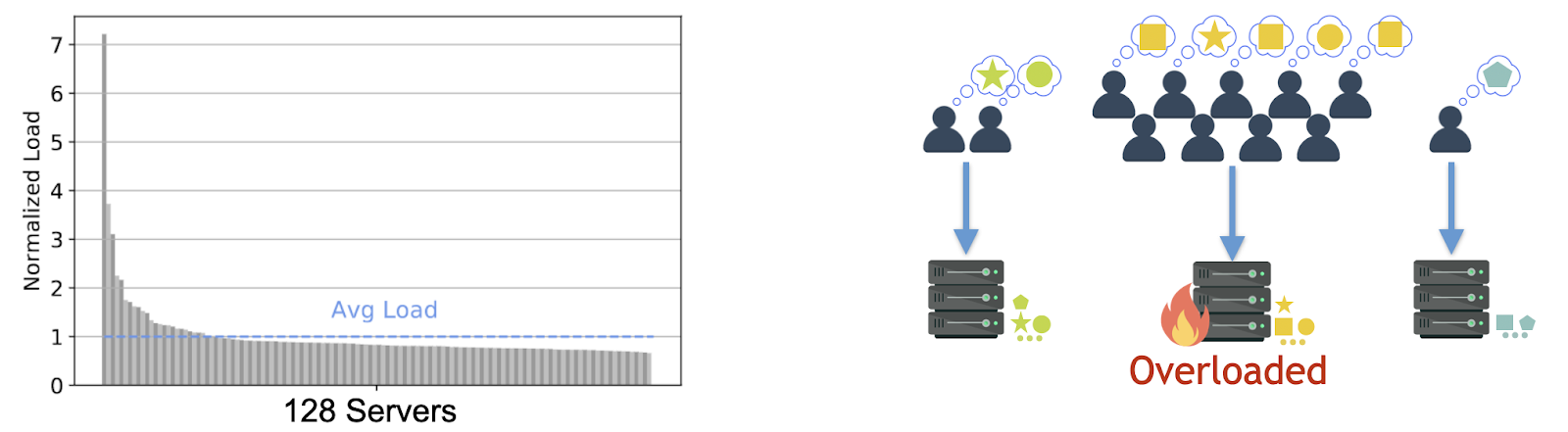
Servers in a modern distributed datastore are interconnected with RDMA and can access each other’s memory. This highly resembles a single-server NUMA architecture where multiple sockets within a server are interconnected and able to access the memory of other sockets. In this latter setting, each processor in a different socket is equipped with its local cache that exploits skew to increase its local accesses and performance.
Solution 1: Inspired by this single-server architecture, we turn skew into an opportunity for distributed datastores to boost their performance. We propose an architecture that balances the request load over a pool of RDMA-connected servers (e.g., a rack). Each server is equipped with a small replicated software cache storing the (same) most popular objects in the pool, and client requests are evenly spread across the pool. Read requests for popular objects are collaboratively served by these symmetric caches, filtering the skew. With the skew filtered, the remaining requests leverage an uncongested RDMA network to complete quickly.

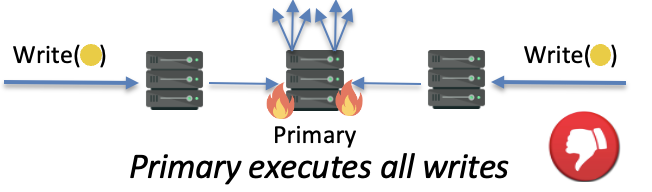
The main challenge, however, is ensuring local reads with strong consistency between the replicated hot objects. Existing protocols provide strong consistency by serializing writes over a physical ordering point (e.g., a primary or directory node), which could itself quickly become a hotspot under skewed accesses. To resolve this issue, we introduced Galene, a protocol that couples multiprocessor-inspired invalidations with logical timestamps to enable fully distributed write coordination from any replica and avoid hotspots. Our evaluation shows that for typical modest write ratios, the proposed scheme powered by Galene improves throughput by 2.2x when compared with the state-of-the-art skew mitigation technique.
Stop Summary
 | Mythology: Galene → The goddess of calm seas, brings balance and tranquility to turbulent waters, as the NUMA-inspired coherent caching balances load to maximize performance under turbulent access skew. Insight: (1) Just like NUMA + caching → RDMA + caching (2) Caching and replication are similar! Contrary to conventional wisdom: (1) Skew is a friend, not a foe. (2) Strong consistency with high performance — despite aggressively replicating the hottest objects. Folklore to ignore: “Only two hard things in computer science: cache invalidations and naming things.” More info: [Eurosys’18], https://s.a-phd.com |
[Stop 2] Hermes: Fault-tolerant Invalidation-based replication
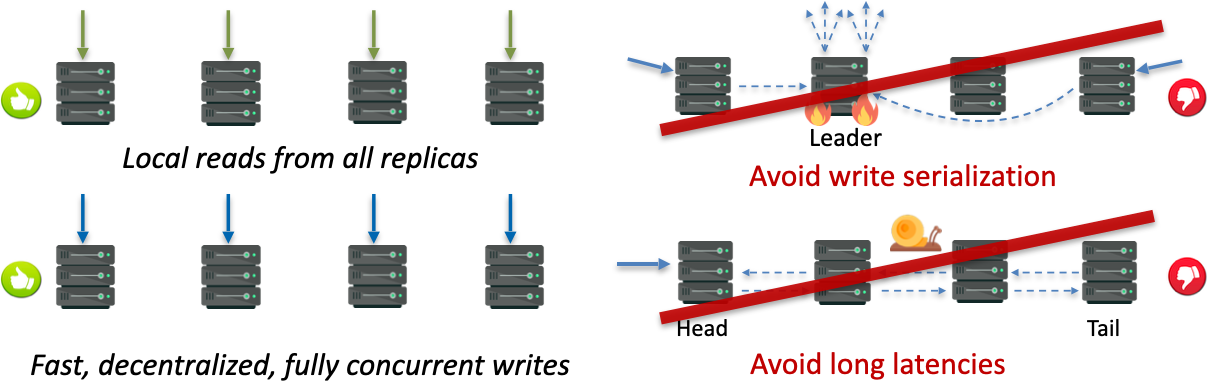
Challenge 2: Reliable datastores must replicate their data using protocols capable of strong consistency and fault tolerance. Existing strongly consistent replication protocols deliver fault tolerance but fall short in terms of performance. Briefly, they treat fault-free execution almost as costly as execution when faults occur and do not offer local reads and fast writes from all replicas. Meanwhile, the opposite happens in the world of multiprocessors, where data are replicated across the private caches of different cores. The multiprocessor regime uses invalidations to afford strong consistency with local reads and fast writes but neglects fault tolerance.
Although handling failures in the datacenter is critical for data availability, failures at the level of an individual server in a datacenter are relatively infrequent. Data from Google show that an average server fails at most twice per year. In other words, the common operation within a replica group closely resembles that of a multiprocessor.
Solution 2: To address this conundrum, we introduced Hermes, an invalidation-based protocol for datastores that is strongly consistent and fault tolerant while exploiting the typical fault-free operation to enable local reads and fast writes from all replicas. We show that a cache-coherent-inspired invalidating protocol can be made resilient and deliver high throughput with low latency.
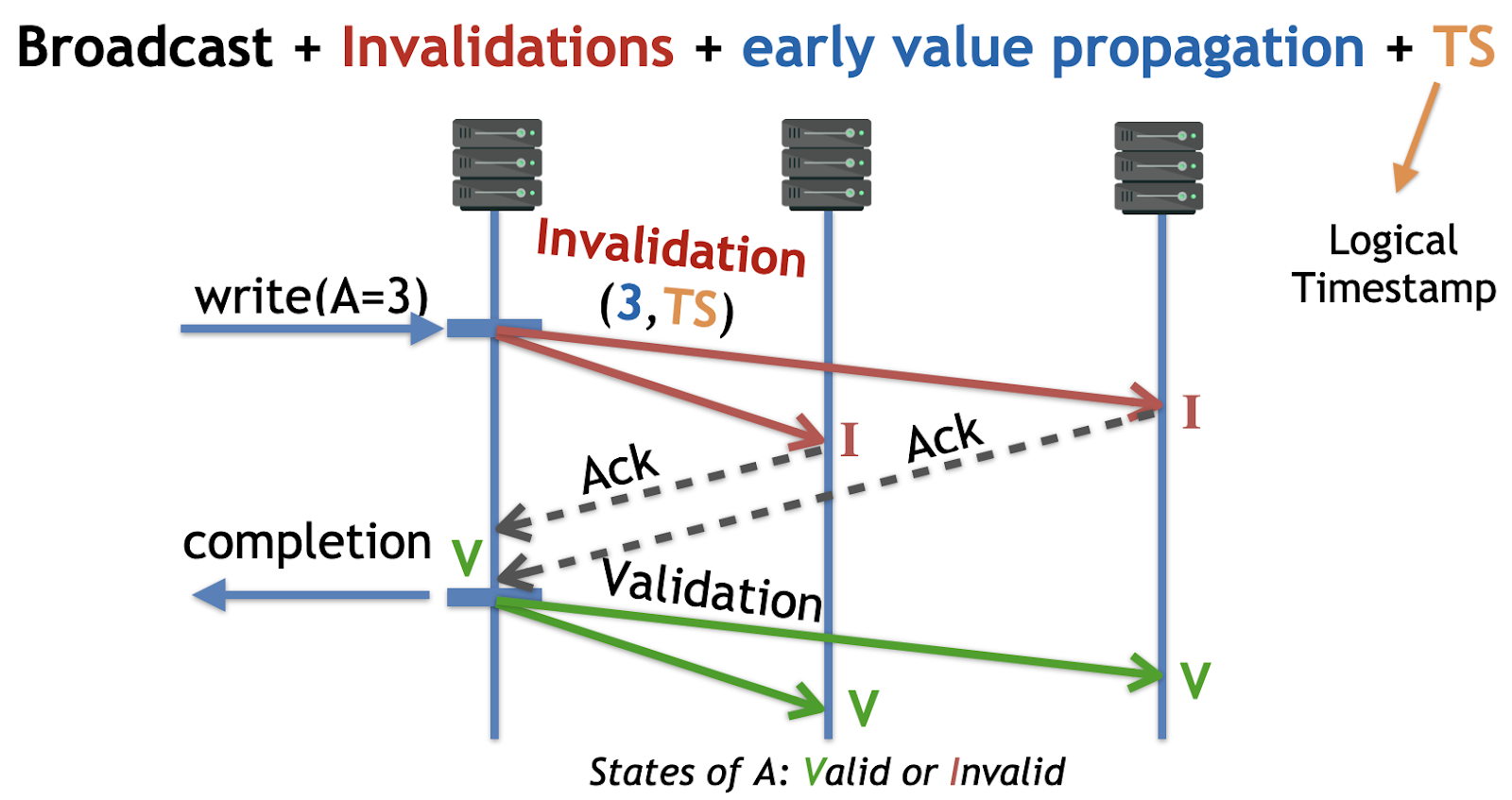
Hermes builds upon Galene’s two main ideas to achieve high performance while additionally ensuring fault tolerance. The first idea is the use of invalidations, a form of lightweight locking inspired by cache coherence protocols. The second is per-key logical timestamps implemented as Lamport clocks. Together, these enable linearizability; local reads; and fully concurrent, decentralized, and fast writes. Logical timestamps further allow each node to locally establish a single global order of writes to a key, which enables conflict-free write resolution (i.e., writes never abort).
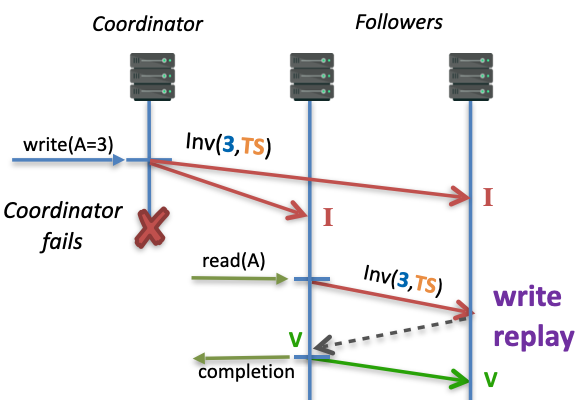
The issue, however, is that in traditional invalidation-based protocols, a replica server failure in the middle of a write can permanently leave another replica blocked in an Invalid state. Hermes addresses this through the introduction of idempotent write replays. Eagerly transmitting the new value along with its timestamped invalidation allows any Invalid replica to safely replay the write in an idempotent way using the same invalidation message with the original value and timestamp and unlock itself.
Five server replicas managed by Hermes afford hundreds of millions of reads and writes per second, resulting in significantly higher throughput than the state-of-the-art fault-tolerant protocols while offering strong consistency and more than 3.6x lower tail latency.
Stop Summary
 | Mythology: Hermes → Messenger of the Gods and a conductor of souls into the afterlife. Insight: Fault-free execution … (1) largely dominates over the execution during faults. (2) resembles coherence in multiprocessors (i.e., Replication Coherence). (3) in existing protocols is costly, as they forfeit local reads and fast writes from all replicas. Contrary to conventional wisdom: Fast, strongly consistent, and fault-tolerant replication — with local reads & fast writes from all replicas Folklore to ignore: “Paxos is the most practical replication protocol.” More info: [ASPLOS’20], https://hermes-protocol.com |
To be continued!
Editor: Tianyin Xu (UIUC) and Dong Du (Shanghai Jiao Tong University)